AI is great for solving problems that couldn’t be solved with classical computing, and improving performance in other areas. However, there has been too much fuss over having a lot of data and deep learning. This belief generally translates to either 1) only Google or Microsoft can come up with great AI products (because they have more data than anyone else), or 2) we need to have our big data infrastructure ready to incorporate AI. While having lots proprietary data, and a state of the art big data infrastructure can provide you a competitive advantage, not having it shouldn’t prevent you from venturing into / incorporating AI.
The AI Decision Flow diagram below illustrates when to use what algorithms / modelling techniques. The diagram below focuses on Decision Flow for Classification used in recommendation engines, categorization (e.g. fraud vs. no-fraud) and pattern recognition (e.g. character / handwriting recognition). The principle idea is to start with the simplest approach requiring the least data.
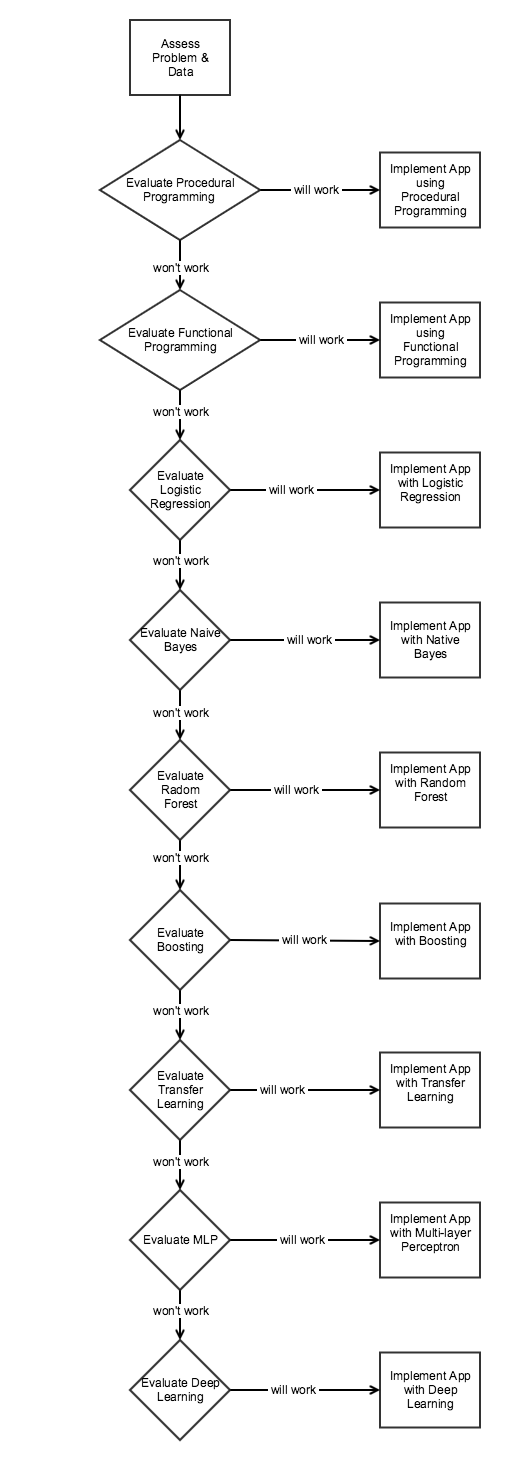
Notes:
a) There are several other classification techniques – e.g. kNN, SVM, Decision Trees. Techniques such as kNN can be used to build great recommendation engines (e.g. Amazon Product Recommendation).
b) Transfer learning is an increasingly popular approach where you can use models trained for other purposes to develop custom solutions. It is a viable first step in many scenarios.
The following factors need to be considered when developing AI solutions.
- All commercial programming languages support procedural programming. Procedural programming is relatively simple and can easily incorporate rules based reasoning, case based reasoning, financial engineering algorithms, etc. The core of many AI applications are written in C/C++ using procedural programming techniques.
- Functional programming enables developers to focus more mathematics and worry less about programming. Functional programming is also used to implement Machine Learning. Most AI applications implement functional paradigms, and can be implemented using Python, Scala and Java (version 1.8 or greater).
- Logistic regression in combination with feature engineering and heuristics is often used as benchmark, even if it is not the final solution.
- Naive Bayes despite its theoretical limitations often yields surprisingly good results.
- Random Forests and Boosting can often beat out Deep Learning, especially when there is less data. XGBoost in particular can deliver impressive results. However, GPU accelerated Deep Learning may be faster than GPU accelerated XGBoost.
- Transfer Learning is a very broad topic but increasingly common practice. In some scenarios it could be the first steps.
- Deep Learning with MLPs or CNNs can deliver great result. But require a lot of data and computing cycles.
Rationale for this approach:
- Data Acquisition Cost: Data acquisition can be time consuming and costly. It is not sufficient to have data, it also has to be pre-processed (cleaned, normalized and labeled). Classical machine learning and transfer learning can significantly reduce data acquisition costs.
- Computing Cost: Improving GPU performance and memory capacity has reduced costs. This will continue to improve, however, some Deep Learning tasks continue to take hours / days.
- Human Skills / Cost: More and more libraries and tools are available. These can reduce work effort involved when developing solutions. However, human skills is a key success factor and plays a key role in enabling the development and delivery of great AI products and solutions.
Product companies developing innovative AI solutions can use limited amount of data to launch their initial products. As users adopt the products, companies can gather more data over time (See Data Adoption Cycle diagram below). Enterprises can adopt a similar strategy to acquire data and in parallel build out their AI infrastructure.
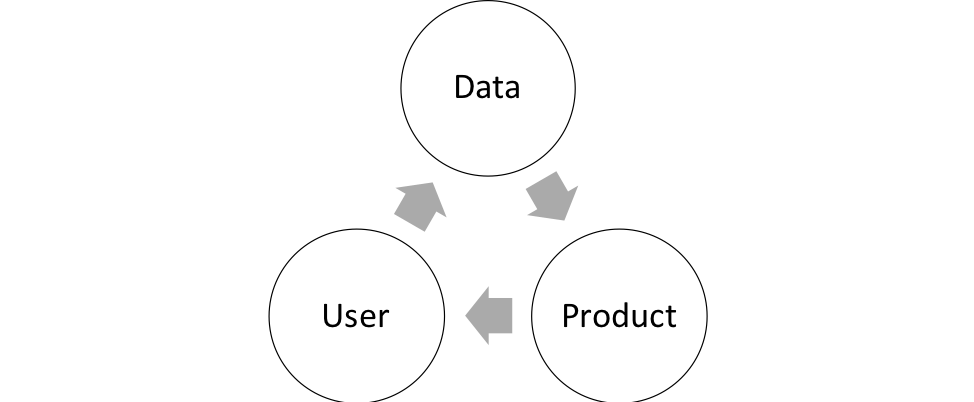
The above data acquisition cycle was originally presented and recommended by Andrew Ng.
